Privacy in the Age of Generative AI


On a recent trip to my hometown in Eastern Canada, my father picked me up at the airport. One of the first things he asked me was, “Is AI going to take everyone’s jobs?”.
When AI, generative AI, and large language models (LLM) have become topics of conversation within the senior citizen community of rural Canada, you know it’s on everyone’s minds. Generative AI, and especially the use of LLMs, is the “new new thing”. It dominates my X (i.e. Twitter) feed and nearly every conversation I have about technology.
There’s justifiably a ton of excitement about the power of generative AI, reminiscent of the introduction of the Internet or the first smartphone. Generative AI is poised to transform how we build products, design drugs, write content, and interact with technology. But as the utilization of AI grows, many governments and companies have raised concerns about the privacy and compliance issues that adopters of these technologies face.
The core challenge posed by generative AI right now is that unlike conventional applications, LLMs have no “delete” button. There’s no straightforward mechanism to “unlearn” specific information, no equivalent to deleting a row in your database’s user table. In a world where the “right to be forgotten” is central to many privacy regulations, using LLMs presents some difficult challenges.
So what does all this mean for businesses that are building new AI-powered applications or AI models?
In this post, we’ll explore this question and attempt to provide answers. We’ll examine the potential impact of generative AI, ongoing compliance hurdles, and a variety of privacy strategies. Finally, we’ll examine a novel approach grounded in the IEEE’s recommended architecture for securely storing, managing, and utilizing sensitive customer PII (Personally Identifiable Information)—the data privacy vault.
Generative AI’s privacy and compliance challenges
Imagine the following scenario: You’ve just copied and pasted sensitive contract details into an LLM to get some quick assistance with routine contract due diligence. The LLM serves its purpose, but here’s the catch: depending on how it’s configured, that confidential contract data might linger within the LLM, accessible to other users. Deleting it isn’t an option, predicting its future use—or misuse—becomes a daunting task, and retraining the LLM to “roll it back” to its state before you shared those sensitive contract details can be prohibitively expensive.
The only foolproof solution?
Keep sensitive data far away from LLMs.
Sensitive information, including internal company project names, core intellectual property, or personal data like birthdates, social security numbers, and healthcare records, can inadvertently find its way into LLMs in several ways:
- Training data: LLMs are trained and honed on expansive datasets that often contain PII. Without robust anonymization or redaction measures in place, sensitive data becomes part of the model’s training dataset, meaning that this data can potentially resurface later.
- Inference: LLMs generate text based on user inputs or prompts. Much like training data, a prompt containing sensitive data seeps into the model and can influence the generated content, potentially exposing this data.
Privacy laws
AI data privacy is a formidable challenge for any company interested in investing in generative AI technology. Recent temporary bans of ChatGPT in Italy and by companies like Samsung have pushed these concerns to the forefront for businesses looking to invest in generative AI.
Even outside of generative AI, there are increasing concerns about protecting data privacy. Meta was recently fined $1.3 billion by the European Union (EU) for its non-compliant transfers of sensitive data to the U.S. And this isn’t just an issue for companies doing business in the EU.
There are now more than 100 countries with some form of privacy regulation in place. Each country’s privacy regulations include unique and nuanced requirements that place a variety of restrictions on the use and handling of sensitive data. The most common restrictions relate to cross-border data transfers, where sensitive data can be stored, and to individual data subject rights such as the “right to be forgotten.”
One of the biggest shortcomings of LLMs is their inability to selectively delete or “unlearn” specific data points, such as an individual’s name or date of birth. This limitation presents significant risks for businesses leveraging these systems.
For example, privacy regulations in Europe, Argentina, and the Philippines (just to name a few) all support an individual’s “right to be forgotten.” This grants individuals the right to have their personal information removed or erased from a system. Without an LLM delete button, there’s no way for a business to address such a request without retraining their LLM from scratch.
Consider the European Union’s General Data Protection Regulation (GDPR), which grants individuals the right to access, rectify, and erase their personal data—a task that becomes daunting if that data is embedded within an LLM. GDPR also empowers individuals with the right to object to automated decision-making, further complicating compliance for companies that use LLMs.
Data localization requirements pose another challenge for users of LLMs. These requirements pertain to the physical location where customer data is stored. Different countries and regions have precise laws dictating how customer data should be handled, processed, stored, and safeguarded. This poses a significant challenge when using an LLM used for a company’s global customer base.
Data Subject Access Requests (DSARs) under GDPR and other laws add another layer of complexity. In the EU and California, individuals (i.e., “data subjects”) have the right to request access to their personal data, but complying with such requests proves challenging if that data has been processed by LLMs.
Considering the intricate privacy and compliance landscape and the complexity of LLMs, the most practical approach to maintaining compliance is to prevent sensitive data from entering the model altogether. By implementing stringent data handling practices, businesses can mitigate the privacy risks associated with LLMs, while also maintaining the utility of the model. Many companies have already decided that the risks are too high, so they’ve banned the use of ChatGPT, but this approach is shortsighted. Properly managed, these models can create a lot of value.
Privacy approaches for generative AI
To address the privacy challenges associated with generative AI models, there have been a few proposals such as banning or controlling access, using synthetic data instead of real data, and running private LLMs.
Banning ChatGPT and other generative AI systems isn’t an effective long-term strategy, and these other “band aid” approaches are bound to fail as people can find easy workarounds. Using synthetic data replaces sensitive information with similar-looking but non-sensitive data and keeps PII out of the model, but at the cost of losing the value that motivated you to share sensitive data with the LLM in the first place. The model loses context, and there’s no referential integrity between the synthetically generated data and the original sensitive information.
The most popular approach to addressing AI data privacy, and the one that’s being promoted by cloud providers like Google, Microsoft, AWS, and Snowflake, is to run your LLM privately on their infrastructure.
For example, with Snowflake’s Snowpark Model Registry, you can take an open source LLM and run it within a container service in your Snowflake account. They state that this allows you to train the LLM using your proprietary data.

However, there are several drawbacks to using this approach.
Outside of privacy concerns, if you’re choosing to run an LLM privately rather than take advantage of an existing managed service, then you’re stuck with managing the updates, and possibly the infrastructure, yourself. It’s also going to be much more expensive to run an LLM privately. Taken together, these drawbacks mean running a private LLM likely doesn’t make sense for most companies.
But the bigger issue is that, from a privacy standpoint, private LLMs simply don’t provide effective data privacy. Private LLMs give you model isolation, but they don’t provide data governance in the form of fine-grained access controls: any user who can access the private LLM can access all of the data that it contains. Data privacy is about giving a user control over their data, but private LLMs still suffer from all of the intrinsic limitations around data deletion that are blocking the adoption of public LLMs.
What matters to a business—and individual data subjects—is who sees what, when, where, and for how long. Using a private LLM doesn’t give you the ability to make sure that Susie in accounting sees one type of LLM response based on her job title while Bob in customer support sees something else.
So how can we prevent PII and other sensitive data from entering an LLM, but also support data governance so we can control who can see what and support the need to delete sensitive data?
A new approach to PII management
In the world of traditional data management, an increasingly popular approach to protecting the privacy of sensitive data is through the use of a data privacy vault. A data privacy vault isolates, protects, and governs sensitive customer data while facilitating region-specific compliance with laws like GDPR through data localization.
With a vault architecture, sensitive data is stored in your vault, isolated outside of your existing systems. Isolation helps ensure the integrity and security of sensitive data, and simplifies the regionalization of this data. De-identified data that serve as references to the sensitive data are stored in traditional cloud storage and downstream services.
De-identification happens through a tokenization process. This is not the same as LLM tokenization, that has to do with splitting texts into smaller units. With data de-identification, tokenization is a non-algorithmic approach to data obfuscation that swaps sensitive data for tokens. A token is a pointer that lets you reference something somewhere else while providing obfuscation.Traditional data management versus a data privacy vault architec

Let’s look at a simple example. In the workflow below a phone number is collected by a front end application. The phone number, along with any other PII, is stored securely in the vault, which is isolated outside of your company’s existing infrastructure. In exchange, the vault generates a de-identified representation of the phone number (e.g. ABC123). The de-identified (or tokenized) data has no mathematical connection with the original data, so it can’t be reverse engineered.
Any downstream services—application databases, data warehouse, analytics, any logs, etc.—store only a token representation of the data, and are removed from the scope of compliance:
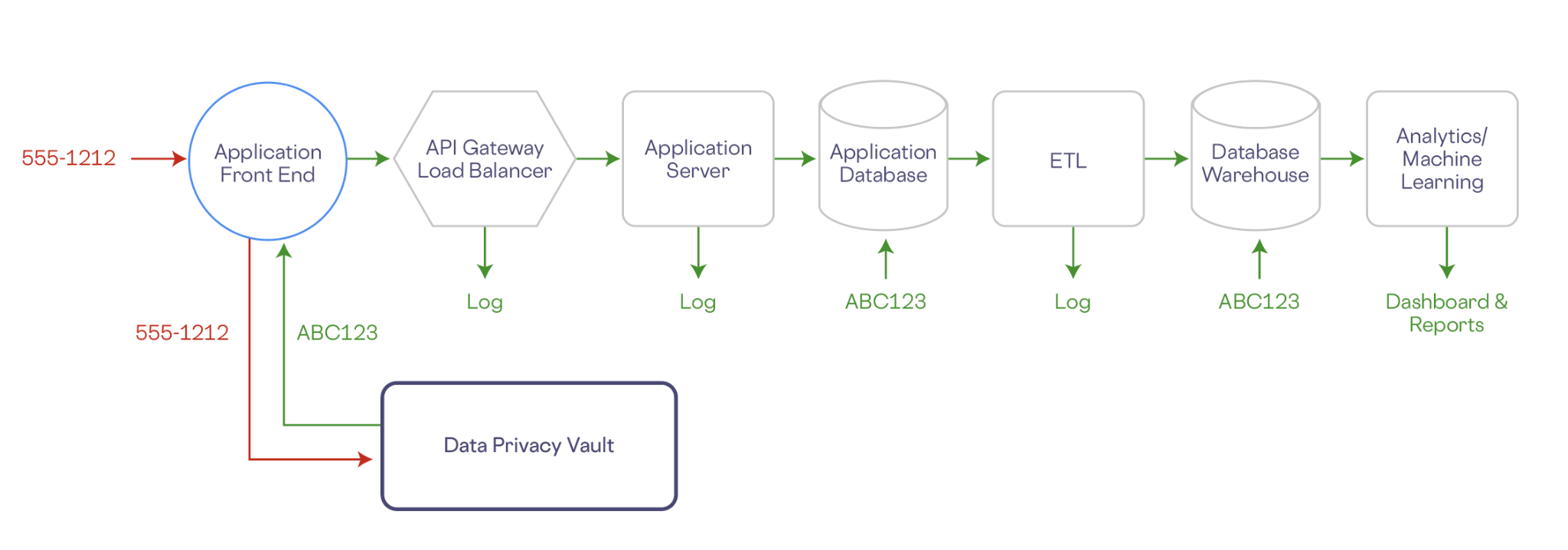
Additionally, a data privacy vault can store sensitive data in a specific geographic location, and tightly control access to this data. Other systems, including LLMs, only have access to non-sensitive de-identified data.
The vault not only stores and generates de-identified data, but it tightly controls access to sensitive data through a zero trust model where no user account or process has access to data unless it’s granted by explicit access control policies. These policies are built from the bottom, granting access to specific columns and rows of PII. This allows you to control who sees what, when, where, for how long, and in what format.
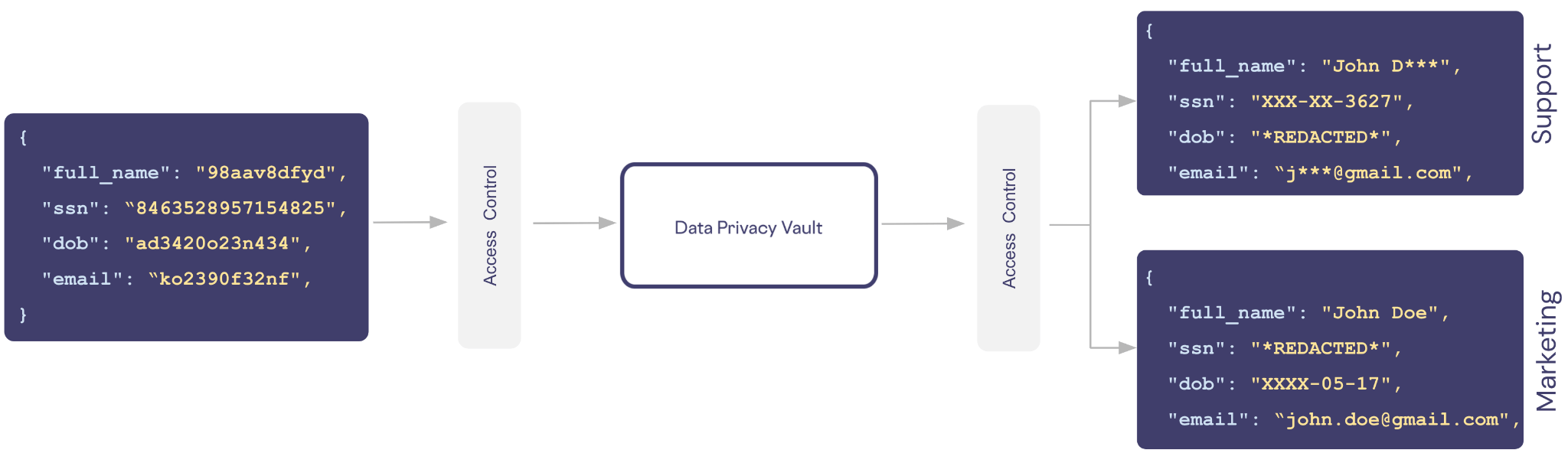
For example, let’s say we have a vault containing customer records with columns defined for a customer’s name, social security number (SSN), date of birth (DOB), and email. In our application we want to support two types of users: support and marketing.
Support doesn’t need to know the exact details about a customer, they only need masked data so they can speak to the customer by name and verify their identity using the last four digits of the customer’s SSN. We can create a policy for the role support that grants access to only the limited view of the data.
ALLOW READ ON users.full_name, users.ssn, users.email WITH REDACTION = MASKED
ALLOW READ ON users.dob WITH REDACTION = REDACTEDSimilarly, a marketing person needs someone’s name and email, but they don’t need the customer’s SSN or need to know how old someone is.
ALLOW READ ON users.full_name, users.email WITH REDACTION = PLAIN_TEXT
ALLOW READ ON users.dob WITH REDACTION = MASKED
ALLOW READ ON users.ssn WITH REDACTION = REDACTEDWith roles and policies similar to ones above in place, the same de-identified data is exchanged with the vault. Based on the role and associated access control policies for the caller, different views of the same sensitive data can be supported.
A privacy firewall for LLMs
Companies can address privacy and compliance concerns with LLMs with a similar application of the data privacy vault architectural pattern. A data privacy vault prevents the leakage of sensitive data into LLMs, addressing privacy concerns around LLM training and inference.
Because data privacy vaults use modern privacy-enhancing technologies like polymorphic encryption and tokenization, sensitive data can be de-identified in a way that preserves referential integrity. This means that responses from an LLM containing de-identified data can be re-identified based on zero trust policies defined in the vault that let you make sure that only the right information is shared with the LLM user. This lets you make sure Susie in accounting only sees what she should have access to (i.e., account numbers and invoice amounts) while Bob in customer support sees only what he needs to do his job.
Preserving privacy during model training
To preserve privacy during model training, the data privacy vault sits at the head of your training pipeline. Training data that might include sensitive and non-sensitive data goes to the data privacy vault first. The vault detects the sensitive data, stores it within the vault, and replaces it with de-identified data. The resulting dataset is de-identified and safe to share with an LLM.

An LLM doesn’t care whether my name, Sean Falconer, is part of the training data or some consistently generated representation of my name (such as “dak5lhf9w”) is part of the training data. Eventually, it’s just a vector.
Preserving privacy during inference
Sensitive data may also enter a model during inference. In the example below, a prompt is created asking for a summary of a will. The vault detects the sensitive information, de-identifies it, and shares a non-sensitive version of the prompt with the LLM.
Since the LLM was trained on non-sensitive and de-identified data, inference can be carried out as normal.

On egress from the LLM, the response is passed through the data privacy vault for re-identification. Any de-identified data will be re-identified assuming the end-user has the right to see the information, according to explicit access control policies configured in the vault.
Privacy and compliance
From a privacy and compliance standpoint, using a data privacy vault means that no sensitive data is ever shared with an LLM, so it remains outside of the scope of compliance. Data residency, DSARs, and delete requests are now the responsibility of a data privacy vault that’s designed to handle these requirements and workflows.
Incorporating the vault into the model training and inference pipelines allows you to combine the best of modern sensitive data management with any LLM stack, private, public, or proprietary.
Final thoughts
As every company gradually morphs into an AI company, it’s critically important to face data privacy challenges head-on. Without a concrete solution to data privacy requirements, businesses risk remaining stuck indefinitely in the “demo” or “proof-of-concept” phase. The fusion of data privacy vaults and generative AI offers a promising path forward, freeing businesses to harness the power of AI without compromising on privacy.
 Sean’s been an academic, startup founder, and Googler. He has published works covering a wide range of topics from information visualization to quantum computing. Currently, Sean is Head of Marketing and Developer Relations at Skyflow and host of the podcast Partially Redacted, a podcast about privacy and security engineering. You can connect with Sean on Twitter @seanfalconer.
Sean’s been an academic, startup founder, and Googler. He has published works covering a wide range of topics from information visualization to quantum computing. Currently, Sean is Head of Marketing and Developer Relations at Skyflow and host of the podcast Partially Redacted, a podcast about privacy and security engineering. You can connect with Sean on Twitter @seanfalconer.