GraphQL vs. REST: What Are They, and Which Is Better for You?

Web development has exploded in complexity and dynamism over the last decade. Of all the paradigms created during this period, two have bubbled to the top: GraphQL and REST. Each has significantly impacted how we build things digitally, and each has its unique approach to data retrieval and exchange. This article aims to demystify these technologies, offering a clear comparison to help developers make informed decisions. Let’s start with a high-level overview of GraphQL and REST.
Understanding GraphQL
What is GraphQL?
GraphQL is a query language developed by Facebook in 2012, aimed at making data fetching more efficient and tailored to the needs of modern web applications. It allows clients to request exactly the data they need, nothing more, nothing less, which can significantly reduce the amount of data transferred between the client and server.
Imagine you’re at a buffet (the server) where an extensive array of dishes (data) is available. In a traditional buffet, you might be given a plate (the API response) with portions of every dish available, regardless of your taste or appetite. This is akin to traditional REST APIs, where the server defines what data is available in each endpoint, often leading to over-fetching (getting more data than you need) or under-fetching (needing to make additional requests for more data).
With GraphQL, you’re free to choose exactly what dishes you want and in what quantity. You can select your preferred dishes (specific data fields), specify the amount of each (query depth and complexity), and even mix ingredients from different dishes to create a custom plate (combining data from multiple sources in one request). This “choose-what-you-need” approach reduces waste (bandwidth and memory usage) and ensures you get exactly what you want (the data needed for the application).
At the heart of a GraphQL endpoint is the schema. Designing a GraphQL schema is a foundational step in building a GraphQL API, necessitating a collaborative and strategic approach among cross-functional teams, including product managers, developers, and designers. This process not only outlines the structure of the API but also ensures that the product’s data needs align with the user experience and business objectives.
A GraphQL schema serves as a contract between the client and the server, detailing the types of data available and the ways clients can interact with that data. It is defined using GraphQL’s Schema Definition Language (SDL). It specifies queries for retrieving data, mutations for modifying data, and subscriptions for real-time updates, ensuring a comprehensive blueprint for data interaction.
If you are working with an engineering team that divides itself into many domains, then the schema design process encourages early and ongoing collaboration between product managers, developers, and designers across the domains. This multidisciplinary approach ensures that the schema reflects the product’s requirements and user needs accurately. Designing with the end user in mind ensures that the schema is intuitive and aligns with user expectations, leading to a better user experience.
Exploring REST
What is REST?
REST stands for Representational State Transfer, an architectural style defining a set of constraints for creating web services. It operates through standard HTTP methods and treats server objects as resources that can be created, retrieved, updated, or deleted.
Each endpoint in a REST API corresponds to a specific resource or a collection of resources. The design revolves around resource identification, representation, and the actions that can be performed on them. Designing endpoint paths with consideration for resource relationships and hierarchy can make the API more intuitive but should be used judiciously to avoid overly complex URLs.
Identifying the resources and modeling the domain are critical first steps, necessitating the product team to have a thorough comprehension of the business entities. This can lead to more upfront discussions on endpoint structure, resource naming conventions, and resource relationships. REST involves designing multiple endpoints, each corresponding to a specific resource or a collection of resources. This requires more collaboration between frontend and backend teams to ensure the endpoints match client application workflows.
Comprehensive documentation is essential for ensuring that developers understand how to use the API. Tools like Swagger (OpenAPI) can automate documentation and provide interactive interfaces for testing endpoints.
Similarities and Distinctions
Common Ground
GraphQL and REST are both firmly rooted in the client-server model. This architecture separates the user interface concerns from the data storage concerns, allowing developers to build more scalable and maintainable systems. At their core, both GraphQL and REST are about simplifying the communication process between clients (such as web or mobile applications) and servers. They provide a structured way to query and manipulate data over the internet, making it easier for developers to build interactive, data-driven applications.
When to Use GraphQL
GraphQL’s single evolving schema allows for easier iterative development and feedback loops. Teams can add fields and types without affecting existing queries, enabling smoother evolution of the API as user needs and business requirements change. For example, frontend teams can specify exactly what data they need for their own feature, they can work on specific portions of the schema without impacting other teams, which can lead to more efficient discussions on data requirements and less back-and-forth communication.
Consider a financial application for managing corporate expense cards where a user’s dashboard might display a feed of transactions, notifications, payment cards, and money transfers, all of which are interconnected data points. With GraphQL, the frontend can make a single query to fetch all required data simultaneously.
For example:
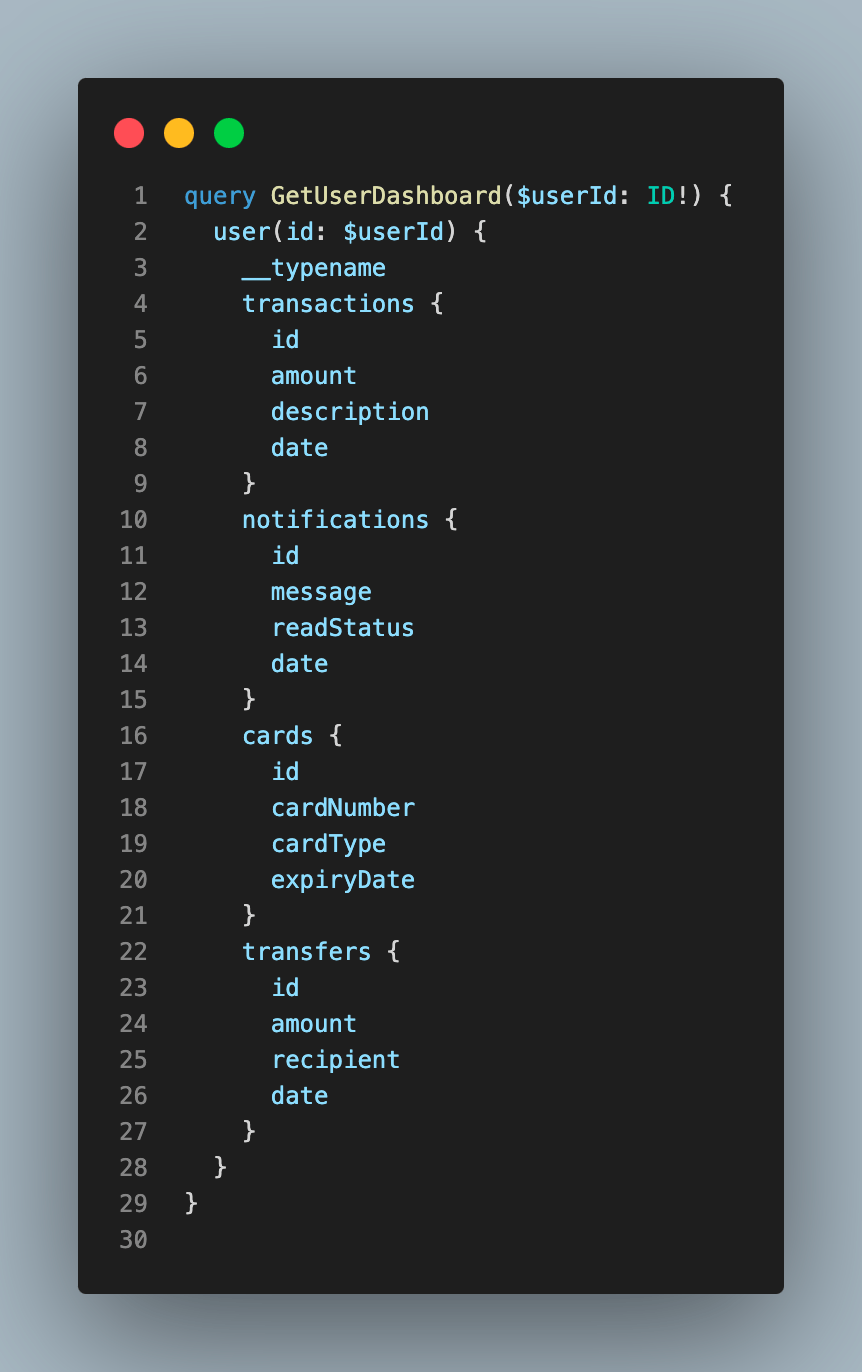
Let’s say, for instance, the transaction team wants to support new features such as categorizing transactions or adding merchant details. In GraphQL, this can be achieved without impacting the existing schema or the work of other teams. Let’s say our current schema definition looks like the following:

The transaction team could opt to extend the Transaction type with a new Merchant type:

Then update the resolver for the Transaction type:

Now, say the Card Issuance team wants to support a set of Security features that involves authorized access to card details (i.e. cvv / pin ). They would work on extending the Card type.

When updating the resolver, the can not only quickly add another resolver for the field but also apply field-level permissions to the team a newly created field.
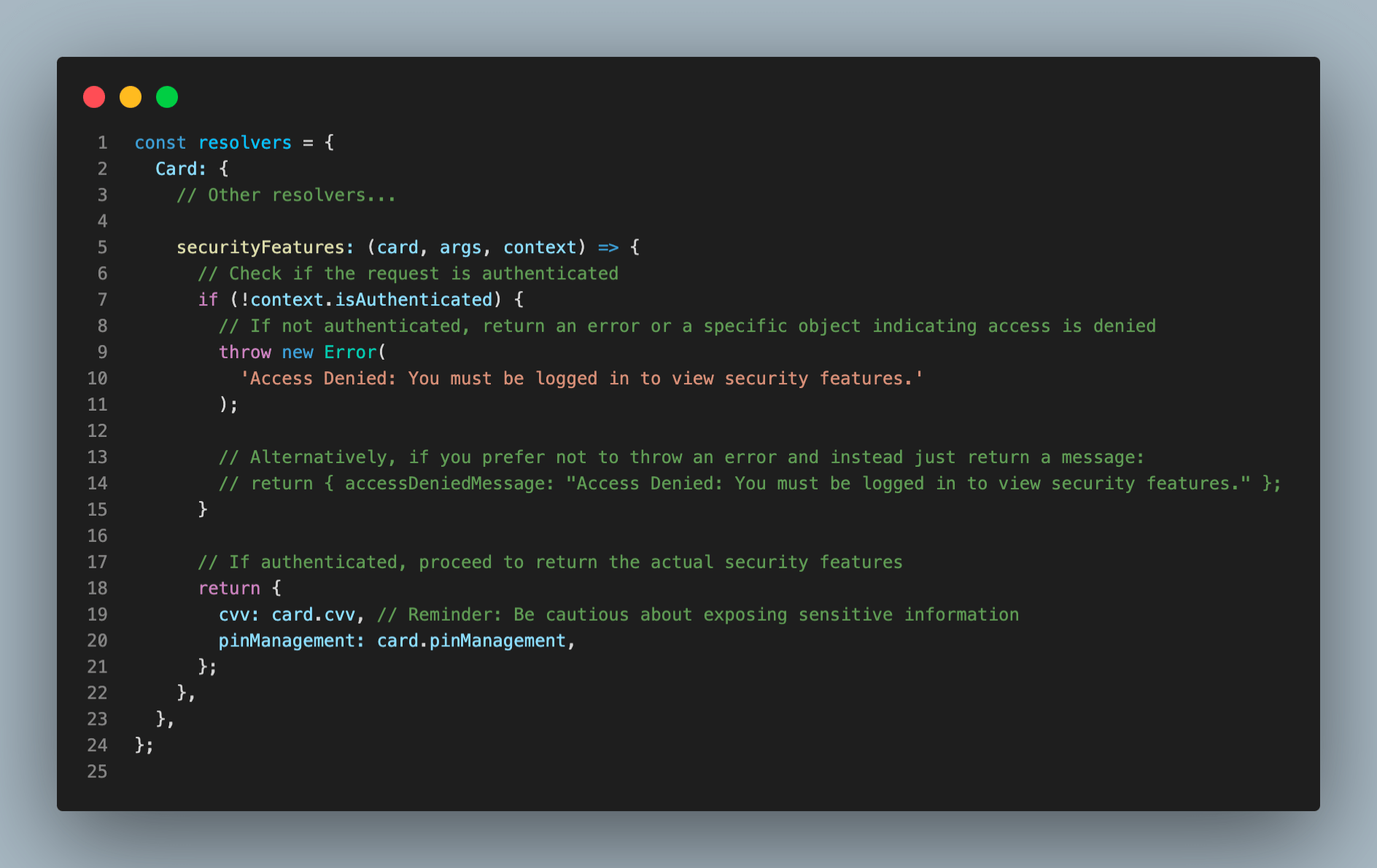
When to Use REST
REST tends to be best suited for a few particular scenarios. For example, applications that are straightforward or that heavily rely on caching. It also tends to be best with data models with a relatively flat structure, where resources (the entities or objects in your application) are easily identified and accessed directly through URLs. REST can also be a very effective approach if your application’s data can be represented as a collection of simple, independent entities without complex interrelations.
Other areas where REST is helpful are if the use case requires clear resource identification. Each resource in a RESTful API is identified by a unique URL, making it clear what each endpoint represents and how it can be interacted with. This simplicity in identifying and accessing resources contributes to the overall straightforwardness of using REST. Given its standardized nature, REST is often preferred for APIs where extensive documentation and ease of consumption are crucial.
Example Scenario with REST
In a RESTful API architecture, resources such as transactions, notifications, cards, and transfers are typically accessed through distinct endpoints. Implementing new features like SecurityFeatures for a resource involves considering both the endpoint design and the security model, ensuring that sensitive information is only accessible to authorized users. Here’s how this could be structured and secured:
RESTful Endpoints
- Transactions: GET /api/users/{userId}/transactions
- Notifications: GET /api/users/{userId}/notifications
- Payment Cards: GET /api/users/{userId}/cards
- Money Transfers: GET /api/users/{userId}/transfers
For a comprehensive dashboard view, the client would need to make separate requests to each of these endpoints. This could be particularly challenging in scenarios with limited bandwidth or high latency, as the cumulative delay from multiple round trips could degrade the user experience significantly. To populate this view, the app makes four separate API calls:
- Fetch transactions to show recent spending activity.
- Fetch notifications to alert the user to any important updates or actions required.
- Fetch payment cards to allow the user to select a card for new transactions or to manage existing cards.
- Fetch money transfers to review recent transfers or to initiate new ones.
Each call waits for a response before the dashboard can fully render, leading to a visible delay for the end user.
From a development perspective, adding the SecurityFeatures section to the existing card resource endpoint is different from the GraphQL implementation. This section would include sensitive data related to a payment card, such as CVV or PIN management capabilities, which should only be available to authenticated and authorized users. One common approach to securing this data with REST is using middleware in the server that processes requests. Middleware can intercept requests before they reach the endpoint logic, allowing the server to authenticate and authorize requests.
Choosing the Right Tool
The choice between GraphQL and REST is not a matter of superiority but of suitability. GraphQL offers unparalleled flexibility and efficiency for complex, data-intensive applications, while REST shines in its simplicity, cacheability, and standardization. The decision should be guided by the project’s specific requirements, available development resources, and scalability considerations.
Kevin Ruan is an implementation engineer at Highnote. Kevin started his career in engineering at the financial services firm SS&C Advent, and has over 12 years of experience leading engineering initiatives for technology teams at some of the world’s most well-known software companies, including Snowflake, SnapLogic, and Google. Kevin has a Bachelor’s degree in computer science from Oregon State University and a Master’s degree in computer science from Georgia Institute of Technology.